This year, I decided to participate in the Posit Table Contest. Because I’m a fan of the great tables Python library I thought it would be great to enhance my mastery of this beautiful library by designing a table. I’ll use the Polars library for data munging and transformation.
Data collection
The data was collected from the Transport Security Administration website, which has archived data on the number of airport passenger checkings done daily from 2019 to 2023. The data was then saved as a parquet file containing columns Date and Numbers.
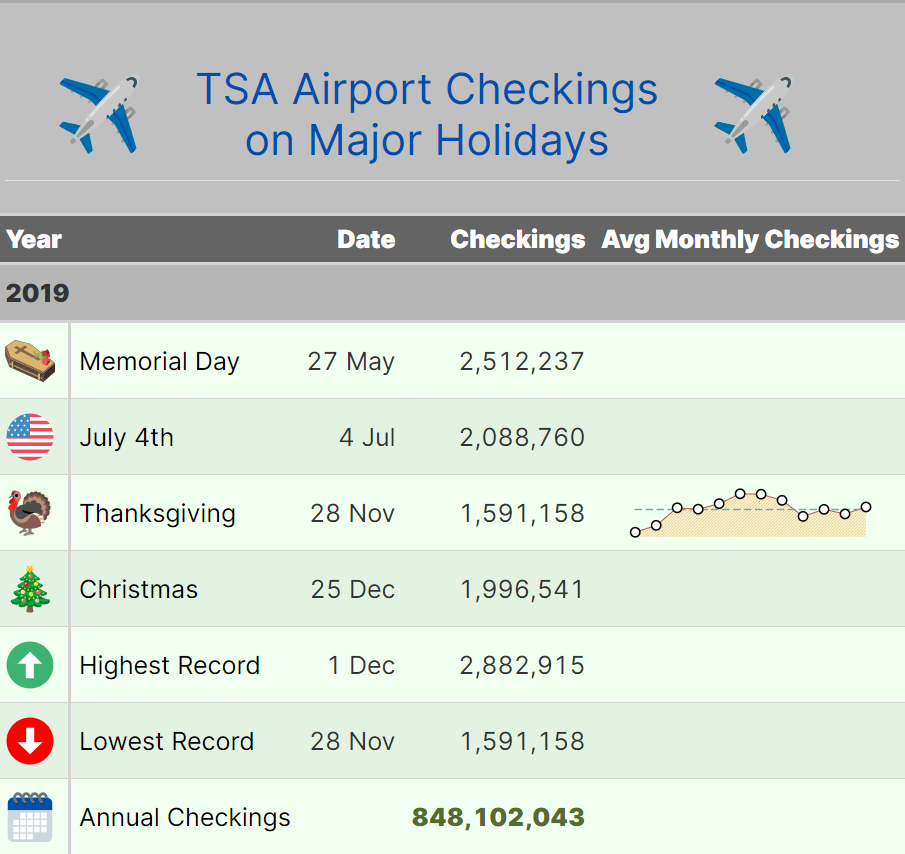
 TSA Airport Checkings
TSA Airport Checkings





